 Hace unos días veíamos algunas cosas sobre los virus y cómo funcionan, y dejábamos pendiente una explicación detallada del virus CIH, popularmente conocido como Chernobyl. Pues bien, les presento un análisis pormenorizado de esta simpática criatura: cómo funciona, cómo infecta a otros programas y cómo logra dejarnos el ordenador como salido de un accidente nuclear.
Hace unos días veíamos algunas cosas sobre los virus y cómo funcionan, y dejábamos pendiente una explicación detallada del virus CIH, popularmente conocido como Chernobyl. Pues bien, les presento un análisis pormenorizado de esta simpática criatura: cómo funciona, cómo infecta a otros programas y cómo logra dejarnos el ordenador como salido de un accidente nuclear.
Y aclarado esto, empecemos diciendo que una parte importante de los programas es el control de errores: cuando un programa “la pifia?, el sistema retoma el control e intenta salvar los muebles. En el caso de los virus, si hay un error durante la ejecución no nos interesa para nada que el sistema se entere, por lo que vamos a modificar el manejador de las excepciones para que el SO no se entere de nada. Para los amantes del rigor, el virus modifica el SEH (Structure Exception Handle). Así, si hay un error, en principio el virus retendrá el control de la situación.
Lo siguiente es ver cómo modificar los permisos con los que el programa se ejecuta. En Windows la seguridad está configurada en forma de anillos, que delimitan determinadas zonas. El primer anillo corresponde a los procesos del SO, y las aplicaciones que se ejecutan en este anillo tienen acceso a todo el sistema. El siguiente anillo tiene menos permisos, y así sucesivamente.
Las aplicaciones de usuario se ejecutan en principio en el tercer anillo, el llamado (seguro que no lo imaginan) “Ring 3?. La idea es que nuestro virus se convierta discretamente en una aplicación “Ring 0? para poder acceder a todo el sistema.
Para hacer esto es necesario vulnerar el mecanismo de protección, pero estos mecanismos en Windows 9x no estaban demasiado pulidos, de modo que el virus se servía de determinadas vulnerabilidades para hacer este cambio de anillo. Para quienes veneran el rigor técnico sobre el bien y el mal, habrá que decir que semejante cosa se consigue modificando la IDT (Interrupt Descriptor Table, Tabla de descriptores de interrupciones) y generando después una excepción, lo que le permitirá ejecutar su código con los permisos más elevados del sistema.
Una vez “trapicheado? el sistema, el virus se coloca en la memoria como un programa cualquiera y, como ya sugerimos en la entrega anterior, espera a que se ejecute alguna aplicación. Previamente habrá devuelto el control al programa “portador? para que haga lo que tenga que hacer.
Bien, ya tenemos nuestro virus en memoria esperando para atacar. Cuándo se cargue en memoria una posible víctima intentará la infección: Lo primero será comprobar si es un ejecutable de Windows y que no haya sido infectado anteriormente ¿cómo sabe esto último? Cuando infecta un fichero escribe un valor distinto del original (cero) en el primer byte antes de la cabecera del ejecutable.
Lo siguiente es “inyectar? el código maligno en el ejecutable, sin aumentar el tamaño del mismo. Pero esto no parece sencillo… ¿cómo lo logra? Digamos que en las cabeceras de los ejecutables de Windows se almacenan diversos datos relativos a las funciones que importan o exportan, información que el programa necesita y demás. Todos estos datos se organizan en “objetos?, que tienen que estar organizados de una forma muy concreta dentro del fichero del programa. A su vez, hay que guardar dónde se encuentran estos objetos, qué tamaño ocupan… todo esto se hace con tablas, por lo que el principio del ejecutable consiste en un montón de descriptores y tablas.
Entre todas estas secciones queda un espacio que no se usa, que es el que aprovecha el virus para escribir su código sin incrementar el tamaño del programa portador. Previamente habrá comprobado que tiene el espacio suficiente para infectar el fichero, y en caso contrario no lo hará. Por desgracia, CIH es una pequeña maravilla en cuando a tamaño, ya que sólo ocupa aproximadamente un 1KB, con lo cual casi siempre encontrará huecos en los que instalarse.
Una vez insertado su código, modifica la cabecera para que la dirección de entrada al ejecutable quede apuntando a su propio código.
El payload (carga dañina)
El payload varía entre versiones, pero generalmente lo que hace es obtener el mes y el día y comprobar si es el día 26 de abril. En caso afirmativo, comienza a sobreescribir el chip de la BIOS (si es de tipo flash).
Seguro que algún lector se pregunta algo así como “¿pero la BIOS no es una memoria de sólo lectura? ¿cómo consigue escribir entonces??. La respuesta es que la BIOS es de sólo lectura en principio, pero que generalmente se puede modificar aplicando cierto voltaje*. Normalmente las placas bases impiden que se suministre este voltaje al chip, pero cuando el virus CIH se extendió, tal protección solía venir inhabilitada para facilitar las actualizaciones de la BIOS, con lo que la información quedaba expuesta.
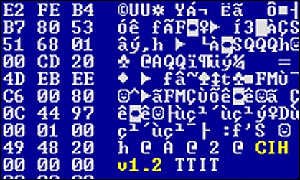
Cuando termine con esto, localizará los discos duros del sistema y escribirá datos aleatorios sobre los primeros 2048 sectores, dejándolos inutilizables.
El CIH se encuentra prácticamente extinguido a fecha de hoy, gracias a que los sistemas Windows 9x van cayendo en desuso en favor de los basados en Windows NT (saber más). Se trata de un virus muy bien programado, toda una muestra de la belleza que puede encontrarse en la destrucción… Su creador, el taiwanés Chen Ing Hau, (nótese que sus iniciales son las letras C.I.H.) fue detenido en el año 2000.
* Si alguien tiene curiosidad sobre cómo puede ser esto, debe saber que amenazo con dedicarle una entrada al tema en breve.
Actualización: Menear el artículo (¡gracias, Taikochu!)
 Seguro que se ha enfrentado ya a una de estas simpáticas y fascinantes criaturas que son los virus informáticos. O si no usted, probablemente algún conocido suyo los haya sufrido. O tal vez esté infectado y ni siquiera lo sospeche… (sienta cómo la paranoia se apodera de su mente)
Seguro que se ha enfrentado ya a una de estas simpáticas y fascinantes criaturas que son los virus informáticos. O si no usted, probablemente algún conocido suyo los haya sufrido. O tal vez esté infectado y ni siquiera lo sospeche… (sienta cómo la paranoia se apodera de su mente)


 No suelo hacer estas cosas, pero esta vez tengo que reconocer que no he podido resistirme.
No suelo hacer estas cosas, pero esta vez tengo que reconocer que no he podido resistirme.