¿Se puede considerar Internet como la mayor base de datos que existe en la actualidad? Es una pregunta complicada, pero vamos a contestarla. Vayamos por partes… La primera cuestión es si consideramos o no Internet como una base de datos. Si efectivamente lo hacemos, es sin duda la mayor base de datos que existe en el mundo…
¿Qué es una base de datos? Sin más, es una colección de datos almacenados de forma sistemática. Actualmente, la aplastante mayoría de las bases de datos son electrónicas, debido fundamentalmente a las facilidades que proporciona la informática en el tratamiento de datos (tenemos que recordar que el primer computador de la era moderna fue desarrollado para realizar el censo de los EEUU).
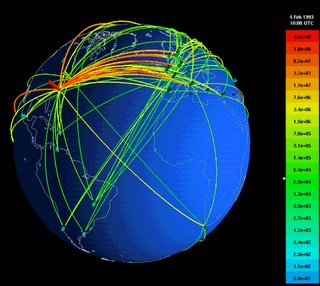
A la hora de incorporar datos a una recopilación, ésto puede hacerse de muchas maneras. Es decir, para almacenar información necesitamos un «esqueleto», un método que nos diga cómo organizarlo todo. Siendo técnicos, a ésto lo llamamos «modelo de datos».
Hay bases de datos que siguen una organización jerárquica, como formando un árbol. Otras tienen una estructura más dinámica y caótica, y se organizan en forma de red. El modelo que usan la mayoría de las bases de datos es el modelo relacional. De ahí que tal vez le suene haber leído «base de datos relacional». Hay, como digo, muchos tipos de organizaciones, y con probabilidad, irán apareciendo nuevos «paradigmas» con el paso del tiempo. Éstas organizaciones son formas que tenemos de hacer la información clasificable y relacionable automáticamente, no tienen otra utilidad que esa.
Sin embargo, Internet no parece seguir una estructura definida, es más bien una gigantesca maraña desorganizada de información. Según eso, y aceptando la definición de base de datos como recopilación de información estructurada, no se puede decir que Internet sea una base de datos. No obstante, tenemos que abrir un poco la mente y para pensar que no todo lo que no obedece unas normas debe ser sistemáticamente menospreciado: los formalismos están bien para ciertas cosas, pero tarde o temprano se nos terminan quedando pequeños.
Así, cuando se definió el modelo entidad-relación (MER) se pensaba que era la tecnología definitiva. Tuvo que llegar Codd y proponer un modelo relacional (MR) muy consistente para que el MER cayera en desuso… y de igual modo, el paradigma de bases de datos orientadas a objetos (OODB o BDOO) amenaza con destruir el MR… Cómo nos gustan las siglas a los informáticos ¿eh?
Desde mi punto de vista, el concepto base de datos es útil en cuanto hace referencia a una recopilación de datos que permite su manipulación, y no en cuanto expresa un conjunto de datos expresados de acuerdo a ciertos formalismos. Con la popularización de la web, y la generalización del uso de los buscadores queda evidenciado que podemos acceder a datos sin que éstos presenten una estructura formalizada, es decir, un «modelo».
Según un estudio de hace unos años, se calcula que el 80% de los datos que las compañías almacenan se encuentran en forma no estructurada (por ejemplo, en vez de estar en la base de datos se encuentran escritos en un fichero de texto). Lo mismo pasa en la web, donde la estructura brilla por su ausencia. Sin embargo, conocemos herramientas que permiten recuperar información de fuentes no estructuradas basándose en palabras clave y otras técnicas. Y cualquier buscador nos permite obtener información sobre millones de fuentes en pocos segundos, mientras que una consulta a una base de datos relacional de tamaño medio puede llevar cierto tiempo si han de cruzarse datos de tablas.
Ésto no quiere decir que deban dejar de utilizarse las bases de datos convencionales, pero hay que tener en cuenta que muchas formas de almacenar la información sin estructura y recuperarla, eran irreales hace unos años y hoy día son completamente viables. Google Desktop Search nos permite indizar (o «indexar», depende de gustos) archivos de nuestro ordenador y hacer búsquedas casi instantáneas, al igual que en la web. ¿Para qué necesitaría entonces formalizar mis datos en una base relacional?
Podemos ver a una base de datos como una «caja» a la que introducimos una consulta y nos devuelve un resultado. Lo mismo podemos hacer en Internet, aunque eso sí, con mecanismos un tanto diferentes. Pero al final el resultado es muy similar: las dos cajas negras nos devuelven la información que queremos.
Si somos estrictos, Internet no puede considerarse una base de datos. Sin embargo, podemos recuperar información relevante de la red en muy poco tiempo y sin demasiado esfuerzo, que es el objetivo que persiguieron los primeros formalismos para bases de datos. Si la web permite almacenar datos y recuperarlos con ciertos mecanismos fiables, ¿por qué no se le puede considerar una base de datos? ¿qué buscamos con una base de datos que nos proporcione Internet?
Desde mi óptica, podemos entender Internet como una enorme entidad capaz de almacenar un conocimiento incuantificable. Si nos vemos desde fuera, esa enorme maraña de cables y equipos es una verdadera red de neuronas que mantiene milagrosamente vivo un conocimiento inabarcable. No nos preguntemos ¿qué es una base de datos? sino ¿para qué nos sirve a los humanos una base de datos? y veremos que no existen motivos que nos impidan otorgar ésta consideración al invento más influyente de los últimos tiempos.
 ¿Qué es un protocolo? ¿Qué pinta ese «http» en la barra del navegador? En la sociedad identificamos ésta palabra con un conjunto de normas o convenciones que usamos al relacionarnos con otros. En cierto sentido, el protocolo es necesario a todos los niveles, por cuanto nos proporciona una seguridad, una forma de «hacer las cosas» que sabemos que está aceptada por el resto.
¿Qué es un protocolo? ¿Qué pinta ese «http» en la barra del navegador? En la sociedad identificamos ésta palabra con un conjunto de normas o convenciones que usamos al relacionarnos con otros. En cierto sentido, el protocolo es necesario a todos los niveles, por cuanto nos proporciona una seguridad, una forma de «hacer las cosas» que sabemos que está aceptada por el resto. Éste es, ciertamente, un blog sobre tecnología bastante atípico… lleva ya unos tres meses de madurez, y como buen padre, me siento razonablemente orgulloso de mi criatura. Concretamente, hay un rasgo con el que estoy encantado: está absolutamente desfasado, anticuado y obsoleto.
Éste es, ciertamente, un blog sobre tecnología bastante atípico… lleva ya unos tres meses de madurez, y como buen padre, me siento razonablemente orgulloso de mi criatura. Concretamente, hay un rasgo con el que estoy encantado: está absolutamente desfasado, anticuado y obsoleto.



{kind=link}